In most time-series applications, especially things like IoT, there's a constant need to find the most recent value of an item or a list of the top X things by some aggregation. Therefore, theyre used in the payment table as a foreign key. A CROSS JOIN returns a combination of all records (a Cartesian product) found in both tables. However, when I wrote my query with more than one JOIN. We'll discuss this more later. That said, as you'll see from the benchmark results, enabling compression in TimescaleDB (which converts data into compressed columnar storage), improves the query performance of many aggregate queries in ways that are even better than ClickHouse. Generally in databases there are two types of fundamental architectures, each with strengths and weaknesses: OnLine Transactional Processing (OLTP) and OnLine Analytical Processing (OLAP). Saving 100,000 rows of data to a distributed table doesn't guarantee that backups of all nodes will be consistent with one another (we'll discuss reliability in a bit). columnar compression into row-oriented storage, functional programming into PostgreSQL using customer operators, Large datasets focused on reporting/analysis, Transactional data (the raw, individual records matter), Pre-aggregated or transformed data to foster better reporting, Many users performing varied queries and updates on data across the system, Fewer users performing deep data analysis with few updates, SQL is the primary language for interaction, Often, but not always, utilizes a particular query language other than SQL, What is ClickHouse (including a deep dive of its architecture), How does ClickHouse compare to PostgreSQL, How does ClickHouse compare to TimescaleDB, How does ClickHouse perform for time-series data vs. TimescaleDB, Worse query performance than TimescaleDB at nearly all queries in the.

Data cant be directly modified in a table, No index management beyond the primary and secondary indexes, No correlated subqueries or LATERAL joins, 1 remote client machine running TSBS, 1 database server, both in the same cloud datacenter. Here is one solution that the ClickHouse documentation provides, modified for our sample data. The open-source relational database for time-series and analytics. We'll go into a bit more detail below on why this might be, but this also wasn't completely unexpected. Non-standard SQL-like query language with several limitations (e.g., joins are discouraged, syntax is at times non-standard). But we found that even some of the ones labeled synchronous werent really synchronous either. We ran many test cycles against ClickHouse and TimescaleDB to identify how changes in row batch size, workers, and even cardinality impacted the performance of each database. Instead, you want to pick an architecture that evolves and grows with you, not one that forces you to start all over when the data starts flowing from production applications. In fact, just yesterday, while finalizing this blog post, we installed the latest version of ClickHouse (released 3 days ago) and ran all of the tests again to ensure we had the best numbers possible! If something breaks during a multi-part insert to a table with materialized views, the end result is an inconsistent state of your data.
But nothing in databases comes for free - and as well show below, this architecture also creates significant limitations for ClickHouse, making it slower for many types of time-series queries and some insert workloads. Bind GridView using jQuery json AJAX call in asp net C#, object doesn't support property or method 'remove', Initialize a number list by Python range(), Python __dict__ attribute: view the dictionary of all attribute names and values inside the object, Python instance methods, static methods and class methods. :this is table t1 and t2 data. To some extent we were surprised by the gap and will continue to understand how we can better accommodate queries like this on raw time-series data. Let's dig in to understand why. The one set of queries that ClickHouse consistently bested TimescaleDB in query latency was in the double rollup queries that aggregate metrics by time and another dimension (e.g., GROUPBY time, deviceId). SQL Server SELECT TOP examples. Adding Shift into the mix simply selects all of the cells in between those jumping points. It's hard to find now where it has been fixed. It supports a variety of index types - not just the common B-tree but also GIST, GIN, and more. 2 rows in set. Finally, depending on the time range being queried, TimescaleDB can be significantly faster (up to 1760%) than ClickHouse for grouped and ordered queries. For this, Clickhouse relies on two types of indexes: the primary index, and additionally, a secondary (data skipping) index. Poor inserts and much higher disk usage (e.g., 2.7x higher disk usage than TimescaleDB) at small batch sizes (e.g., 100-300 rows/batch). These are two different things designed for two different purposes. By clicking Sign up for GitHub, you agree to our terms of service and PostHog as an analytics tool allows users to slice and dice their data in many ways across huge time ranges and datasets. As we've already shown, all data modification (even sharding across a cluster) is asynchronous, therefore the only way to ensure a consistent backup would be to stop all writes to the database and then make a backup. This works well because not every query needs optimizing and a relatively small subset of properties make up most of whats being filtered on by our users. The datasets were created using Time-Series Benchmarking Suite with the cpu-only use case. Could your application benefit from the ability to search using trigrams? All columns in a table are stored in separate parts (files), and all values in each column are stored in the order of the primary key. Similarly, it is not designed for other types of workloads. While it's understandable that time-series data, for example, is often insert-only (and rarely updated), business-centric metadata tables almost always have modifications and updates as time passes. Tables are wide, meaning they contain a large number of columns. As a product, we're only scratching the surface of what ClickHouse can do to power product analytics. In roadmap on Q4 of 2018 (but it's just a roadmap, not a hard schedule). var d = new Date()
As a result, all of the advantages for PostgreSQL also apply to TimescaleDB, including versatility and reliability. document.write(d.getFullYear())
This means asking for the most recent value of an item still causes a more intense scan of data in OLAP databases. Why ClickHouse didn't allow more than one JOIN in query? The results shown below are the median from 1000 queries for each query type. And as a developer, you need to choose the right tool for your workload. If youd like to get data stored in tables joined by a compound key thats a primary key in one table and a foreign key in another table, simply use a join condition on multiple columns. Enabled in master with some restrictions: Nice to here it. From this we can see that the ClickHouse server CPU is spending most of its time parsing JSON. We are fans of ClickHouse. You can find the code for this here and here. More importantly, this holds true for all data that is stored in ClickHouse, not just the large, analytical focused tables that store something like time-series data, but also the related metadata. Learning JOINs With Real World SQL Examples, How to Join Multiple (3+) Tables in One Statement. Temporary Tables ClickHouse supports temporary tables which have the following characteristics: Temporary tables disappear when the session ends, including if the connection is lost. As soon as the truncate is complete, the space is freed up on disk. . Here is a similar opinion shared on HackerNews by stingraycharles (whom we dont know, but stingraycharles if you are reading this - we love your username): "TimescaleDB has a great timeseries story, and an average data warehousing story; Clickhouse has a great data warehousing story, an average timeseries story, and a bit meh clustering story (YMMV).". So, let's see how both ClickHouse and TimescaleDB compare for time-series workloads using our standard TSBS benchmarks. Because ClickHouse isn't an ACID database, these background modifications (or really any data manipulations) have no guarantees of ever being completed. So, if you find yourself needing to perform fast analytical queries on mostly immutable large datasets with few users, i.e., OLAP, ClickHouse may be the better choice. Yet this can lead to unexpected behavior and non-standard queries. The story does change a bit, however, when you consider that ClickHouse is designed to save every "transaction" of ingested rows as separate files (to be merged later using the MergeTree architecture). Again, this is by design, so there's nothing specifically wrong with what's happening in ClickHouse! To avoid this, you can use TOP 1 WITH TIES. The student table has data in the following columns: id (primary key), first_name, and last_name. Already on GitHub? PostHog is an open source analytics platform you can host yourself. Given the focus on data analytics, this was a smart and obvious choice given that SQL was already widely adopted and understood for querying data. Inability to modify or delete data at a high rate and low latency - instead have to batch deletes and updates, Batch deletes and updates happen asynchronously, Because data modification is asynchronous, ensuring consistent backups is difficult: the only way to ensure a consistent backup is to stop all writes to the database. Today we live in the golden age of databases: there are so many databases that all these lines (OLTP/OLAP/time-series/etc.) Stack multiple columns into one with VBA. Issue needs a test before close. We also have a detailed description of our testing environment to replicate these tests yourself and verify our results.

With ClickHouse, it's just more work to manage this kind of data workflow. One last thing: you can join our Community Slack to ask questions, get advice, and connect with other developers (we are +7,000 and counting!). Lets now understand why PostgreSQL is so loved for transactional workloads: versatility, extensibility, and reliability. All tables in ClickHouse are immutable. How can we join the tables with these compound keys? Timescale Cloud now supports the fast and easy creation of multi-node deployments, enabling developers to easily scale the most demanding time-series workloads.

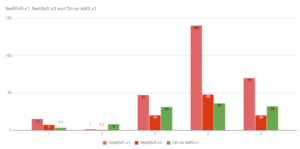
We fully admit, however, that compression doesn't always return favorable results for every query form. It is a very good database built around certain architectural decisions that make it a good option for OLAP-style analytical queries. It's one of the main reasons for the recent resurgence of PostgreSQL in the wider technical community. Other tables can supply data for transformations but the view will not react to inserts on those tables. In one joined table (in our example, enrollment), we have a primary key built from two columns (student_id and course_code). Queries are just a bit ugly but it works. But even then, it only provides limited support for transactions. The properties can include the current URL and any other user-defined properties that describe the event (e.g. Therefore, the queries to get data out of a CollapsingMergeTree table require additional work, like multiplying rows by their `Sign`, to make sure you get the correct value any time the table is in a state that still contains duplicate data. That said, what ClickHouse provides is a SQL-like language that doesn't comply with any actual standard. Choosing the best technology for your situation now can make all the difference down the road. or how do you determine the access path for the base table ? In previous benchmarks, we've used bigger machines with specialized RAID storage, which is a very typical setup for a production database environment. Our database has three tables named student, enrollment, and payment. It has generally been the pre-aggregated data that's provided the speed and reporting capabilities. When these kinds of queries reach further back into compressed chunks, ClickHouse outperforms TimescaleDB because more data must be decompressed to find the appropriate max() values to order by. To overcome these limitations, ClickHouse implemented a series of vector algorithms for working with large arrays of data on a column-by-column basis. By the way, does this task introduce a cost model ? We conclude with a more detailed time-series benchmark analysis. Unlike a traditional OLTP, BTree index which knows how to locate any row in a table, the ClickHouse primary index is sparse in nature, meaning that it does not have a pointer to the location of every value for the primary index. Over the last few years, however, the lines between the capabilities of OLTP and OLAP databases have started to blur. We expected the same thing with ClickHouse because the documentation mentions that this is a synchronous action (and most things are not synchronous in ClickHouse). Unlike inserts, which primarily vary on cardinality size (and perhaps batch size), the universe of possible queries is essentially infinite, especially with a language as powerful as SQL. Instead, if you find yourself needing something more versatile, that works well for powering applications with many users and likely frequent updates/deletes, i.e., OLTP, PostgreSQL may be the better choice. It's hard to find now where it has been fixed. For reads, quite a large number of rows are processed from the DB, but only a small subset of columns. Indeed, joining many tables is currently not very convenient but there are plans to improve the join syntax. ClickHouses limitations / weaknesses include: We list these shortcomings not because we think ClickHouse is a bad database. For simple queries, latencies around 50 ms are allowed. In other words, data is filtered or aggregated, so the result fits in a single servers RAM. ClickHouse is aware of these shortcomings and is certainly working on or planning updates for future releases. In preparation for the final set of tests, we ran benchmarks on both TimescaleDB and ClickHouse dozens of times each - at least. Most of the time, a car will satisfy your needs. We had to add a 10-minute sleep into the testing cycle to ensure that ClickHouse had released the disk space fully. Some of that data might have been moved, and some of it might still be in transit. The typical solution would be to extract $current_url to a separate column.

It turns out, however, that the files only get marked for deletion and the disk space is freed up at a later, unspecified time in the background. Enter your email to receive our newsletter for the latest updates. We actually think its a great database - well, to be more precise, a great database for certain workloads. TIP: SELECT TOP is Microsoft's proprietary version to limit your results and can be used in databases such as SQL Server and MSAccess. Also note that if many joins are necessary because your schema is some variant of the star schema and you need to join dimension tables to the fact table, then in ClickHouse you should use the external dictionaries feature instead. https://clickhouse.yandex/docs/en/roadmap/ These files are later processed in the background at some point in the future and merged into a larger part with the goal of reducing the total number of parts on disk (fewer files = more efficient data reads later). Thank you for all your attention. When new data is received, you need to add 2 more rows to the table, one to negate the old value, and one to replace it. You can see this in our other detailed benchmarks vs. AWS Timestream (29 minute read), MongoDB (19 minute read), and InfluxDB (26 minute read). You made it to the end! As an example, consider a common database design pattern where the most recent values of a sensor are stored alongside the long-term time-series table for fast lookup. Alternative syntax for CROSS JOIN is specifying multiple tables in FROM clause separated by commas. Instead, because all data is stored in primary key order, the primary index stores the value of the primary key every N-th row (called index_granularity, 8192 by default). The payment table has data in the following columns: foreign key (student_id and course_code, the primary keys of the enrollment table), status, and amount. After materializing our top 100 properties and updating our queries, we analyzed slow queries (>3 seconds long). All tables are small, except for one. 6. Note that the student_id and course_code columns form a primary key in the enrollment table. There are batch deletes and updates available to clean up or modify data, for example, to comply with GDPR, but not for regular workloads. (In contrast, in row-oriented storage, used by nearly all OLTP databases, data for the same table row is stored together.). This is a common performance configuration for write-heavy workloads while still maintaining transactional, logged integrity. But if you find yourself doing a lot of construction, by all means, get a bulldozer.. Want to host TimescaleDB yourself? Some synchronous actions arent really synchronous. As you (hopefully) will see, we spent a lot of time in understanding ClickHouse for this comparison: first, to make sure we were conducting the benchmark the right way so that we were fair to Clickhouse; but also, because we are database nerds at heart and were genuinely curious to learn how ClickHouse was built. This impacts both data collection and storage, as well as how we analyze the values themselves. However, because the data is stored and processed in a different way from most SQL databases, there are a number of commands and functions you may expect to use from a SQL database (e.g., PostgreSQL, TimescaleDB), but which ClickHouse doesn't support or has limited support for: One example that stands out about ClickHouse is that JOINs, by nature, are generally discouraged because the query engine lacks any ability to optimize the join of two or more tables. Finally, we always view these benchmarking tests as an academic and self-reflective experience. If the delete process, for instance, has only modified 50% of the parts for a column, queries would return outdated data from the remaining parts that have not yet been processed. Instead, users are encouraged to either query table data with separate sub-select statements and then and then use something like a `ANY INNER JOIN` which strictly looks for unique pairs on both sides of the join (avoiding a cartesian product that can occur with standard JOIN types).
There is at least one other problem with how distributed data is handled. The easiest way to get started is by creating a free Timescale Cloud account, which will give you access to a fully-managed TimescaleDB instance (100% free for 30 days). This is one of the key reasons behind ClickHouses astonishingly high insert performance on large batches. When we ran TimescaleDB without compression, ClickHouse did outperform. By comparison, ClickHouse storage needs are correlated to how many files need to be written (which is partially dictated by the size of the row batches being saved), it can actually take significantly more storage to save data to ClickHouse before it can be merged into larger files. This is a result of the chunk_time_interval which determines how many chunks will get created for a given range of time-series data. How Do You Write a SELECT Statement in SQL? Create a free account to get started with a fully-managed TimescaleDB instance (100% free for 30 days). As developers, were resolved to the fact that programs crash, servers encounter hardware or power failures, disks fail or experience corruption. For example, if # of rows in table A = 100 and # of rows in table B = 5, a CROSS JOIN between the 2 tables (A * B) would return 500 rows total. A temporary table uses the Memory engine only. And of course, full SQL. In this post, Ill walk through a query optimization example that's well-suited to this rarely-used feature. When rows are batched between 5,000 and 15,000 rows per insert, speeds are fast for both databases, with ClickHouse performing noticeably better: However, when the batch size is smaller, the results are reversed in two ways: insert speed and disk consumption. Just creating the column is not enough though, since old data queries would still resort to using a JSONExtract. It's unique from more traditional business-type (OLTP) data in at least two primary ways: it is primarily insert heavy and the scale of the data grows at an unceasing rate. In our benchmark, TimescaleDB demonstrates 156% the performance of ClickHouse when aggregating 8 metrics across 4000 devices, and 164% when aggregating 8 metrics across 10,000 devices. Reliability: no data consistency in backups. This is the basic case of what ARRAY JOIN clause does. Since I'm a layman in database/ClickHouse. For this reason, you want to backfill data. At a high level, MergeTree allows data to be written and stored very quickly to multiple immutable files (called "parts" by ClickHouse). Add pg_trgm. This column separation and sorting implementation make future data retrieval more efficient, particularly when computing aggregates on large ranges of contiguous data.


One of the key takeaways from this last set of queries is that the features provided by a database can have a material impact on the performance of your application. Role-based access control? Essentially it's just another merge operation with some filters applied. Subscribe to our Join our monthly newsletter to be notified about the latest posts. With this table type, an additional column (called `Sign`) is added to the table which indicates which row is the current state of an item when all other field values match. The vast majority of requests are for read access. Join our Slack community to ask questions, get advice, and connect with other developers (the authors of this post, as well as our co-founders, engineers, and passionate community members are active on all channels). As an example, if you need to store only the most recent reading of a value, creating a CollapsingMergeTree table type is your best option. For example, all of the "double-groupby" queries in TSBS group by multiple columns and then join to the tag table to get the `hostname` for the final output. This also means that performance is key when investigating things - but also that we currently do nearly no preaggregation. It's just something to be aware of when comparing ClickHouse to something like PostgreSQL and TimescaleDB. 2 Keyboard Shortcuts to Select a Column with Blank Cells. The SQL SELECT TOP Clause. Some form of transaction support has been in discussion for some time and backups are in process and merged into the main branch of code, although it's not yet recommended for production use. CROSS JOIN is completely different than a CROSS APPLY. What our results didn't show is that queries that read from an uncompressed chunk (the most recent chunk) are 17x faster than ClickHouse, averaging 64ms per query. If we wanted to query login page pageviews in August, the query would look like this: This query takes a while complete on a large test dataset, but without the URL filter the query is almost instant. of unique columns, This would complicate live data ingestion a lot, introducing new and exciting race conditions. Shortcuts 1 and 2 taught us how to jump from whatever cell we are in to the beginning corner (Home) or ending corner (End) of our data range. We'll call this table SensorLastReading. Thank you for taking the time to read our detailed report. The data is automatically filled during INSERT statements, so data ingestion doesn't need to change. PostgreSQL (and TimescaleDB) is like a car: versatile, reliable, and useful in most situations you will face in your life. This table can be used to store a lot of analytics data and is similar to what we use at PostHog. We also acknowledge that most real-world applications don't work like the benchmark does: ingesting data first and querying it second. newsletter for the latest updates. There's no specific guarantee for when that might happen. Specifically, we ran timescaledb-tune and accepted the configuration suggestions which are based on the specifications of the EC2 instance. This difference should be expected because of the architectural design choices of each database, but it's still interesting to see. For this case, we use a broad set of queries to mimic the most common query patterns. Distributed tables are another example of where asynchronous modifications might cause you to change how you query data. Check. migration to ClickHouse from traditional column DBs. ClickHouse was designed with the desire to have "online" query processing in a way that other OLAP databases hadn't been able to achieve. ClickHouse, short for Clickstream Data Warehouse, is a columnar OLAP database that was initially built for web analytics in Yandex Metrica. If your query only needs to read a few columns, then reading that data is much faster (you dont need to read entire rows, just the columns), Storing columns of the same data type together leads to greater compressibility (although, as we have shown, it is possible to build. What about features that benefit time-series data workloads?
We will use the production.products table in the sample database for the demonstration. There is no way to directly update or delete a value that's already been stored. On our test dataset, mat_$current_url is only 1.5% the size of properties_json on disk with a 10x compression ratio. We can see the impact of these architectural decisions in how TimescaleDB and ClickHouse fare with time-series workloads. The key thing to understand is that ClickHouse only triggers off the left-most table in the join. (Which are a few reasons why these posts - including this one - are so long!). :] select * from t1; SELECT * FROM t1 xy 1 aaa xy 2 bbb Progress: 2.00 rows, 32.00 B (635.66 rows/s., 10.17 KB/s.) In the end, these were the performance numbers for ingesting pre-generated time-series data from the TSBS client machine into each database using a batch size of 5,000 rows. Non SQL Server databases use keywords like LIMIT, OFFSET, and ROWNUM. Although ingest speeds may decrease with smaller batches, the same chunks are created for the same data, resulting in consistent disk usage patterns. With vectorized computation, ClickHouse can specifically work with data in blocks of tens of thousands or rows (per column) for many computations. At the end of each cycle, we would `TRUNCATE` the database in each server, expecting the disk space to be released quickly so that we could start the next test. Cheers. The enrollment table has data in the following columns: primary key (student_id and course_code), is_active, and start_date. ClickHouse will then asynchronously delete rows with a `Sign` that cancel each other out (a value of 1 vs -1), leaving the most recent state in the database. Asynchronous data modification can take a lot more effort to effectively work with data. For example, retraining users who will be accessing the database (or writing applications that access the database). Each event has an ID, event type, timestamp, and a JSON representation of event properties. The above query creates a new column that is automatically filled for incoming data, creating a new file on disk. Traditional OLTP databases often can't handle millions of transactions per second or provide effective means of storing and maintaining the data.
Sitemap 4